If you are looking to quickly install ELK Stack, previously known as Elastic stack, then you have come to the right place.
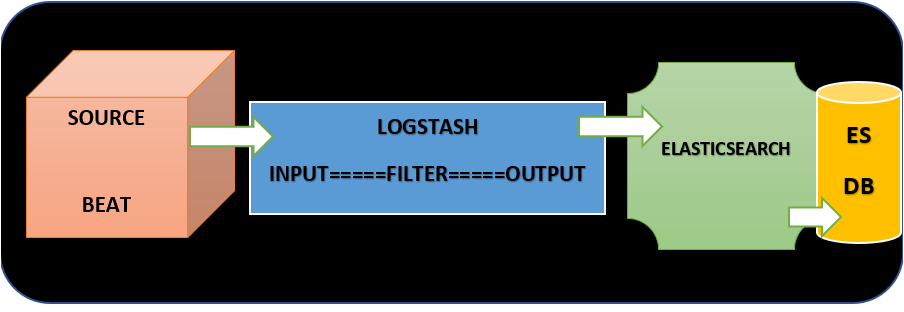
ELK Stack contains mainly four components, i.e., Elasticsearch, Logstash, Kibana Dashboard, Filebeat, and Metricbeat. Combing all these components, it is easier to store, search, analyze, and visualize logs generated from any source in any format.
In this tutorial, you will learn how to install ELK Stack, Elasticsearch, install Logstash, and install Kibana Dashboard on the Ubuntu machine.
Let’s dive in quickly.
Table of Content
- Prerequisites
- How to Install Elasticsearch on ubuntu
- Configuring Elasticsearch on Ubuntu Machine
- How to Install Kibana on ubuntu
- Viewing Kibana Dashboard on Ubuntu Machine
- Verify the Kibana Dashboard
- How to Install Logstash
- Configuring Logstash with Filebeat
- Installing and Configuring Filebeat
- Installing and Configuring Metricbeat
- Verifying the ELK Stack in the Kibana Dashboard
- Conclusion
Prerequisites
- Ubuntu machine preferably 18.04 version + , if you don’t have any machine you can create a ec2 instance on AWS account
- Recommended to have 4GB RAM, at least 5GB of drive space.
- Apache installed on the Ubuntu machine that works as a web server and proxy server.
You may incur a small charge for creating an EC2 instance on Amazon Managed Web Service.
How to Install Elasticsearch on ubuntu
Let’s kick off this tutorial by first installing the first component’s ELK stack that is Elasticsearch, but before you install Elasticsearch, you need to have java installed on the machine.
- Login to Ubuntu machine using your favorite SSH client.
- First, update your existing list of packages by running the below command.
sudo apt update
- Now, install java using the apt install command as shown below.
# Installing Java Version: Java SE 11 (LTS)
sudo apt install default-jdk

- Next, verify the java version on your machine. As you can see below Java has been succesfully installed on ubuntu machine.
java -version # To check the Installed Java Version

- Further add the GPG key for the official Elastic repository to your system. This key builds the trust of your machine with Elastic official repository and enable access to all the open-source software in the ELK stack.
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -

- Install below prerequisites softwares so that apt uses packages over https protocol. The apt transport software allow your machine to connect with external respositories to connect over HTTPS or HTTP over TLS.
sudo apt install apt-transport-https ca-certificates curl software-properties-common
- Now, add the Elastic repository to APT sources so that you can install all the required ELK package.
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee –a /etc/apt/sources.list.d/elastic-7.x.list
- Next, update the system using the following commands.
sudo apt update
- Now its time to Install Elasticsearch with the following command:
sudo apt-get install elasticsearch

Configuring Elasticsearch on Ubuntu Machine
Now that you have successfully installed Elasticsearch on your ubuntu machine, it is important to configure the hostname and the port in the Elasticsearch configuration file. Let’s do it.
- Open the Elasticsearch configuration file with below command and uncomment the network.host, http.port parameter.
vi /etc/elasticsearch/elasticsearch.yml

- In the Elasticsearch configuration file update the discovery.type as below.

- Now, start and enable the Elasticsearch service on the ubuntu machine using below commands.
sudo systemctl enable elasticsearch.service
sudo systemctl start elasticsearch.service


- Finally, verify the Elasticsearch installtion by running the curl command on your machine on port 9200.
curl http://127.0.0.1:9200

How to Install Kibana on ubuntu
Now that you have successfully installed Elasticsearch and configured it. The next component you need to install in the ELK stack is Kibana and view the kibana dashboard. Let’s install Kibana.
- Installing kibana is simple and you need to run a single command as shown below.
sudo apt-get install kibana
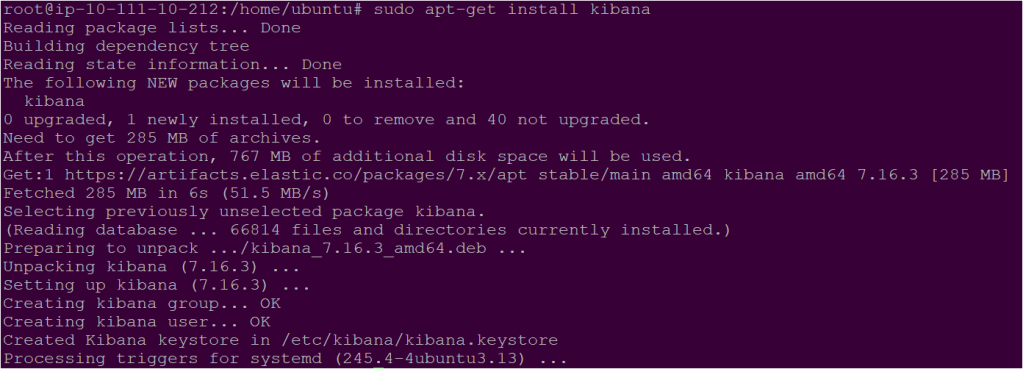
- Now Kibana is installed succesfully. You will need to make changes in configuration file of Kibana as you did earlier for elasticsearch. To make the configuration changes open the kibana.yml configuration file and uncomment the following lines:
server.port: 5601
server.host: "localhost"
elasticsearch.hosts: ["http://localhost:9200"]

Kibana works on Port 5061 by default
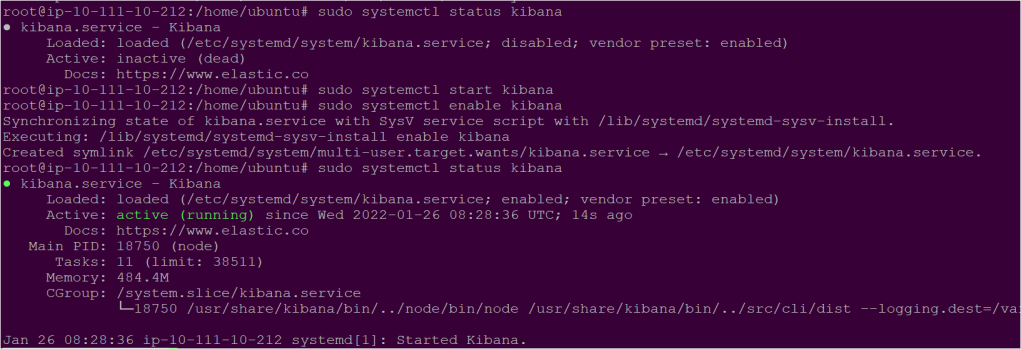
- Once the configuration file is updated, start and enable the Kibana service that you recently installed.
sudo systemctl start kibana
sudo systemctl enable kibana
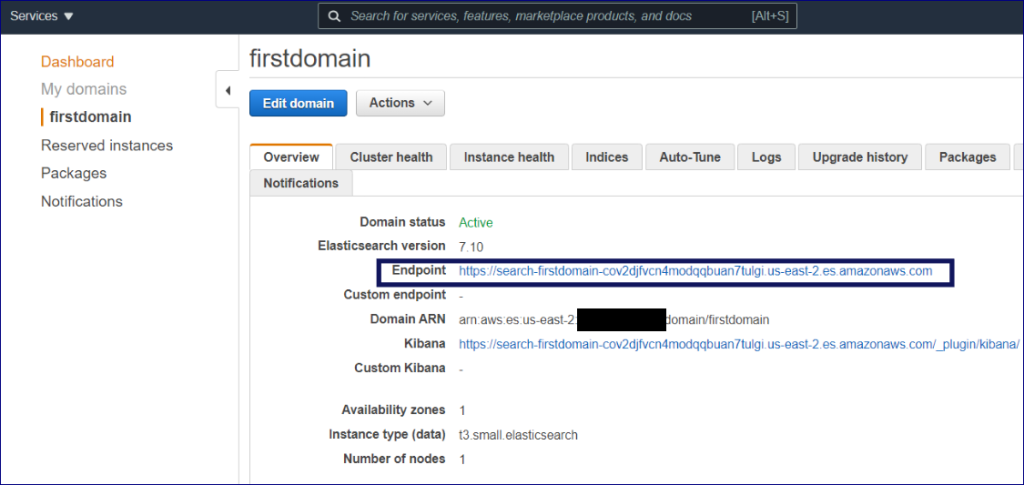
Viewing Kibana Dashboard on Ubuntu Machine
Great, now you have elasticsearch running on Port 9200 and Kibana running on Port 5601. Still, to view the Kibana dashboard on the Ubuntu machine, you need to use the Apache server as your proxy server, allowing the Kibana Dashboard to be viewed on Port 80.
Let’s configure apache to run as a proxy server.
- Create the configuration file named domain.conf in /etc/apache2/sites-available directory and copy/paste the below configuration file.
vi /etc/apache2/sites-available/domain.conf
<VirtualHost *:80>
ServerName localhost
ProxyRequests Off
ProxyPreserveHost On
ProxyVia Full
<Proxy *>
Require all granted
</Proxy>
ProxyPass / http://127.0.0.1:5601/
ProxyPassReverse / http://127.0.0.1:5601/
</VirtualHost>
- After changing the Apache configuration file run the below commands so that apache works as proxy server.
sudo a2dissite 000-default
sudo a2enmod proxy proxy_http rewrite headers expires
sudo a2ensite domain.conf
sudo service apache2 restart
Verify the Kibana Dashboard
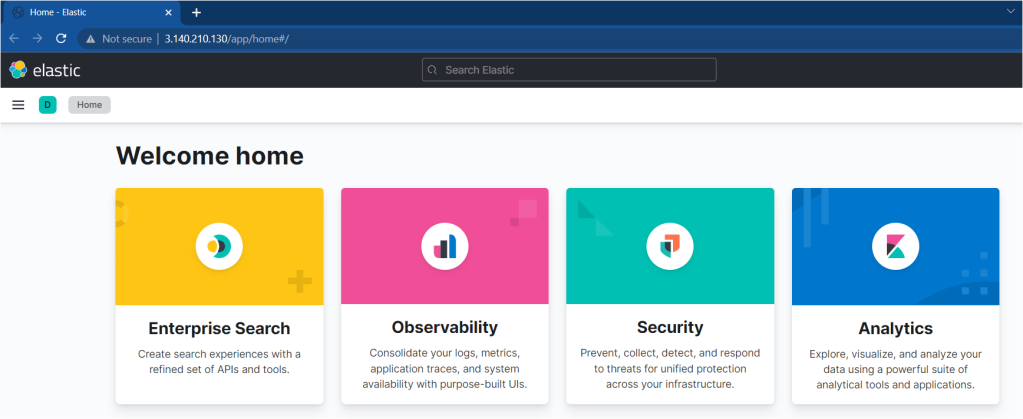
Earlier in the previous section, you installed kibana and configured it to run behind the apache server. Let’s verify by viewing the Kibana dashboard by navigating to the IP address of the server followed by Port 80.
As you can see below, the Kibana dashboard loads successfully.
How to Install Logstash
Logstash is a lightweight, open-source, server-side data processing pipeline that allows you to collect data from various sources, transform it on the fly, and send it to your desired destination. Logstash is a tool that collects data from multiple sources, stores it in Elasticsearch, and is parsed by Kibana.
With that, let’s install the third component used in Elastic Stack. Let’s install Logstash on an Ubuntu machine.
- Install Logstash by running the following command.
sudo apt-get install logstash

- Now start and enable the Logstash by running the systemctl commands.
sudo systemctl start logstash
sudo systemctl enable logstash

- Finally verify the Logstash by running the below command.
sudo systemctl status logstash

Configuring Logstash with Filebeat
Awesome, now you have Logstash installed. You will configure beats in the Logstash; although beats can send the data directly to the Elasticsearch database, it is good to use Logstash to process the data. Let’s configure beats in the Logstash with the below steps.
- Create a file named logstash.conf and copy/paste the below data that allows you to set up Filebeat input .
# Specify the incoming logs from the beats in Logstash over Port 5044
input {
beats {
port => 5044
}
}
# By filter syslog messages are sent to Elasticsearch
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
# Specify output will push logstash logs to an Elastisearch instance
output {
elasticsearch { hosts => ["localhost:9200"]
hosts => "localhost:9200"
manage_template => false
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
- Now test your Logstash configuration with below command. If you see Configuration OK message then the setup is properly done.
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t

- Finally start and enable Logstash with below command.
sudo systemctl start logstash
sudo systemctl enable logstash
Installing and Configuring Filebeat
The Elastic Stack uses lightweight data shippers called beats ( such as Filebeat, Metricbeat ) to collect data from various sources and transport them to Logstash or Elasticsearch. You will learn to install and configure Filebeat on an Ubuntu machine that will be used to push data in Logstash and further to Kibana.
- Install Filebeat on ubuntu machine using following commnads.
sudo apt install filebeat

- Next, edit the Filebeat configuration file so that filebeat is able to connect to Logstash. Uncomment the output.logstash and hosts: [“localhost:5044”] and comment the output.elasticsearch: and hosts: [“localhost:9200”].
vi /etc/filebeat/filebeat.yml
![Uncomment the output.logstash and hosts: ["localhost:5044"]](https://devopsdatacenter.files.wordpress.com/2022/01/image-63.png?w=779)
![comment the output.elasticsearch: and hosts: ["localhost:9200"]](https://devopsdatacenter.files.wordpress.com/2022/01/image-61.png?w=675)
- Next enable the filebeat with below command.
sudo filebeat modules enable system
sudo filebeat setup --pipelines --modules system

- Now, Load the index template from the Filebeat into Logstash by running the below command. Index template are collection of documents that have similar characteristics.
sudo filebeat setup --template -E output.logstash.enabled=false -E 'output.elasticsearch.hosts=["localhost:9200"]'

- Also run the below command so that Logstash can further push to Elasticsearch.
sudo filebeat setup -e -E output.logstash.enabled=false -E output.elasticsearch.hosts=['localhost:9200'] -E setup.kibana.host=localhost:5601

- Now you can start and enable Filebeat.
sudo systemctl start filebeat
sudo systemctl enable filebeat

Installing and Configuring Metricbeat
Previously you learned to install and configure Filebeat, but this time you will learn to install and configure Metricbeat. Metricbeat is a lightweight shipper that you can install on your servers to periodically collect metrics from the operating system and from services running on the server.
- To download and install Metricbeat, open a terminal window and use the commands that work with your system:
curl -L -O https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-7.16.3-amd64.deb
sudo dpkg -i metricbeat-7.16.3-amd64.deb
- From the Metricbeat install directory, enable the system module:
sudo metricbeat modules enable system
- Set up the initial environment for Metricbeat and Start Metricbeat by running the following commands.
sudo metricbeat setup -e
sudo service metricbeat start
Verifying the ELK Stack in the Kibana Dashboard
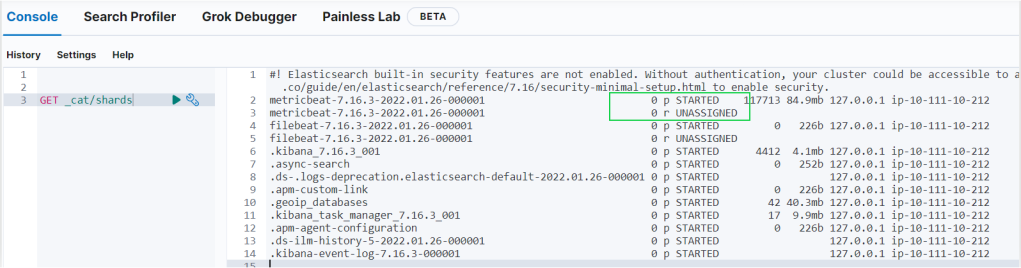
Now that you have your ELK Elastic Stack set up completely. Filebeat and Metricbeat will begin pushing the Syslog and authorization logs to Logstash, then load that data into Elasticsearch. To verify if Elasticsearch is receiving the data, query the index with the below command.
curl -XGET http://localhost:9200/_cat/indices?v
- As you can see below the request is successful, that means the data that was pushed by filebeat is successfully stored in elasticsearch.



Conclusion
In this tutorial, you learned how to install ELK Stack, including installing components, i.e., Elasticsearch, Logstash, Kibana Dashboard, Filebeat, and Metricbeat on the Ubuntu machine.
Now that you have a strong understanding of ELK Stack and all the components, which application do you plan to monitor next?